Infodump update: files relocated, new postlength data January 30, 2012 8:52 AM Subscribe
Infodump update! 1. We've relocated the data files for the Infodump to the mefi.us file server, to better manage load with large file transfers. If you retrieve Infodump files automatically, note the change and update your process accordingly. 2. New data files: postlengths for Mefi, Askme, Meta and Music.
On the file move: only the actual zipped-up data files have moved; the Infodump's index of files is still where it's always been, and if you only grab files manually now and then you will probably not notice any change.
For the moment I've left copies of the updated files in their original spots on the stuff.metafilter.com domain as well, to give folks a chance to notice this and update before anything breaks. At some point, those will go away and attempts to retrieve files from the original urls will start failing, so update soon, nerds!
On the new post length data: we've had comment length data in the Infodump for a couple years now, listing a simple character count for each comment anyone has ever made. That's something that's now available for posts as well.
It's a little more complicated for posts, though, since text can (or could historically) appear in a number of combinations across various posting form fields, depending on the subsite. So instead of providing a single character count, the postlength_* files provide separate counts for the post title, the above-the-fold text area, the below-the-fold text area, and for the case of the mefi file, the url and link fields. Fields that are empty or just not used for a given subsite list a zero.
The Infodump's been out of date for about a month now but should now be back to updating regularly each weekend. Let me know if anything looks broken, and as always feel free to discuss ideas for future improvements to the data.
On the file move: only the actual zipped-up data files have moved; the Infodump's index of files is still where it's always been, and if you only grab files manually now and then you will probably not notice any change.
For the moment I've left copies of the updated files in their original spots on the stuff.metafilter.com domain as well, to give folks a chance to notice this and update before anything breaks. At some point, those will go away and attempts to retrieve files from the original urls will start failing, so update soon, nerds!
On the new post length data: we've had comment length data in the Infodump for a couple years now, listing a simple character count for each comment anyone has ever made. That's something that's now available for posts as well.
It's a little more complicated for posts, though, since text can (or could historically) appear in a number of combinations across various posting form fields, depending on the subsite. So instead of providing a single character count, the postlength_* files provide separate counts for the post title, the above-the-fold text area, the below-the-fold text area, and for the case of the mefi file, the url and link fields. Fields that are empty or just not used for a given subsite list a zero.
The Infodump's been out of date for about a month now but should now be back to updating regularly each weekend. Let me know if anything looks broken, and as always feel free to discuss ideas for future improvements to the data.
Quick question about postlength: is that just a flat character count, or is there some way of calculating "The post is this long but this much of that is just HTML"?
posted by jessamyn (staff) at 9:10 AM on January 30, 2012
posted by jessamyn (staff) at 9:10 AM on January 30, 2012
Remember, I get royalties for coining the word datawankery.
posted by desjardins at 9:13 AM on January 30, 2012 [1 favorite]
posted by desjardins at 9:13 AM on January 30, 2012 [1 favorite]
Just a flat character count, to keep things simple. If anybody wants to tussle with the content of posts in more detail for some sort of analytical fun, that'll need to be more of a one-off thing but I'm happy to oblige so drop me a line.
posted by cortex (staff) at 9:13 AM on January 30, 2012
posted by cortex (staff) at 9:13 AM on January 30, 2012
The longest below-the-fold AskMe winner is... http://ask.metafilter.com/63439
posted by mattbucher at 9:25 AM on January 30, 2012
posted by mattbucher at 9:25 AM on January 30, 2012
Cool. The post length information (or lack thereof) has come up in at least a couple of discussions. I'll have to remind myself what those were about so I can go back and have a look at actual data.
posted by FishBike at 9:26 AM on January 30, 2012
posted by FishBike at 9:26 AM on January 30, 2012
This is just gawping curiosity, but may be the place to ask. How big is Metafilter? I.e., when you do a complete back-up how much disk do you use? I was thinking about this and my guess was that it was actually quite small because it was all just text. But maybe MeFi music has some large media files.
/just curious
posted by benito.strauss at 9:33 AM on January 30, 2012
/just curious
posted by benito.strauss at 9:33 AM on January 30, 2012
20 terabytes, same as in town?
posted by radwolf76 at 9:35 AM on January 30, 2012 [2 favorites]
posted by radwolf76 at 9:35 AM on January 30, 2012 [2 favorites]
How big is Metafilter?
Setting aside the considerable disk space the 5000+ mp3s on Music take up, I think the db is somewhere on the order of 10 GB, but Matt or pb would be able to provide a much better answer.
posted by cortex (staff) at 9:38 AM on January 30, 2012
Setting aside the considerable disk space the 5000+ mp3s on Music take up, I think the db is somewhere on the order of 10 GB, but Matt or pb would be able to provide a much better answer.
posted by cortex (staff) at 9:38 AM on January 30, 2012
To reproduce MetaFilter you will need at least 10 GB and 1 PB.
posted by grouse at 9:41 AM on January 30, 2012 [9 favorites]
posted by grouse at 9:41 AM on January 30, 2012 [9 favorites]
Thanks cortex. Order of magnitude was all I wanted.
10 GB sounds like a small database these days, but that's an awful lot of keystrokes.
posted by benito.strauss at 9:47 AM on January 30, 2012
10 GB sounds like a small database these days, but that's an awful lot of keystrokes.
posted by benito.strauss at 9:47 AM on January 30, 2012
How big is Metafilter?
I've addressed this before.
posted by Rock Steady at 10:16 AM on January 30, 2012 [1 favorite]
I've addressed this before.
posted by Rock Steady at 10:16 AM on January 30, 2012 [1 favorite]
How big is Metafilter?
Let's just say that everyone leaves satisfied.
posted by Meta Filter at 10:19 AM on January 30, 2012 [6 favorites]
Let's just say that everyone leaves satisfied.
posted by Meta Filter at 10:19 AM on January 30, 2012 [6 favorites]
How big is Metafilter?
Large enough to fill an honest man's hand.
posted by The Whelk at 10:32 AM on January 30, 2012
Large enough to fill an honest man's hand.
posted by The Whelk at 10:32 AM on January 30, 2012
Is that counting metafilter.net and the rest of the sites under it's umbrella?
posted by carsonb at 11:28 AM on January 30, 2012
posted by carsonb at 11:28 AM on January 30, 2012
I can't speak to any of the details on Fuelly. As far as I know it's an entirely separate entity as far as hardware and db are concerned. I'd guess the same is true for the others as well.
Also maybe Matt should update the PVRblog item now that he owns it again.
posted by cortex (staff) at 11:34 AM on January 30, 2012
Also maybe Matt should update the PVRblog item now that he owns it again.
posted by cortex (staff) at 11:34 AM on January 30, 2012
The MetaFilter database is 28.3 GB as I type this, Music files alone are 29 GB, and Fuelly is a much smaller 2.3 GB. Yeah, Fuelly is an entirely separate system on separate hardware.
posted by pb (staff) at 1:29 PM on January 30, 2012
posted by pb (staff) at 1:29 PM on January 30, 2012
Man did I lowball that. Although now that I think about it my estimate whenever I came up with that was probably predicated on an accounting of number of characters of text in the main comment and post tables at a byte a pop and without looking at indexing data and other overhead.
In other news, I am not a DBA, I am not your DBA.
posted by cortex (staff) at 1:32 PM on January 30, 2012 [2 favorites]
In other news, I am not a DBA, I am not your DBA.
posted by cortex (staff) at 1:32 PM on January 30, 2012 [2 favorites]
Yeah, since we store all text as Unicode the size is doubled. So throw in a few GB for indexes (including some weighty full-text indexes) and you weren't far off!
posted by pb (staff) at 2:11 PM on January 30, 2012
posted by pb (staff) at 2:11 PM on January 30, 2012
Some historical datapoints, as though from a user who lacks the contextual understanding of what's being discussed and thus assumes any mention of 'gigabytes' must be a proper apples-to-apples comparison and thus of interest to the general readership:
October 2001: Someone asks if MetaFilter would fit on four CDs (~2GB) but no one answers; ads are introduced for the first time.
February 2002: 200MB for the SQL database (plus a couple MB for "the site itself").
February 2002: 100GB/month of bandwidth.
March 2003: 200GB/month of bandwidth.
June 2003: "AskMetaFilter" is discussed in the hypothetical; someone mentions gigabytes.
March 2004: 4GB of RAM in the MeFi server (up from 1GB prior).
April 2004: 120GB of usage on the server's hard drive (including 50GB for MeFi log files alone).
April 2004: 300GB/month of bandwidth "the last I checked."
December 2005: 2.3MB for a Google Earth file plotting the location of the entire locatable MeFi userbase.
February 2006: 150MB/day of log files (50GB of log files deleted at this point; data-retention policy changed).
October 2007: MeFi Mail is rolled out. Lots of GBs are discussed.
May 2009: 12GB for "MeFi database" ("including database cruft like indexes").
May 2009: 5.5GB for just the post/comment content? (plus 15.3GB for music files) [not sure how to square this with the prior entry]
June 2011: Twitter/last.fm/flickr aggregate pages are removed from the site; "gigabytes of data" are reclaimed.
January 2012: 28.3GB for "MetaFilter database" (plus 29GB for music).
posted by nobody at 3:47 PM on January 30, 2012 [7 favorites]
posted by nobody at 3:47 PM on January 30, 2012 [7 favorites]
cortex: Setting aside the considerable disk space the 5000+ mp3s on Music take up, I think the db is somewhere on the order of 10 GB...
Aw, pb beat me to the punch on this. It was surprising that the size of the db & the mp3 are so close. (And another music torrent is overdue.)
posted by Pronoiac at 4:33 PM on January 30, 2012
Aw, pb beat me to the punch on this. It was surprising that the size of the db & the mp3 are so close. (And another music torrent is overdue.)
posted by Pronoiac at 4:33 PM on January 30, 2012
not sure how to square this with the prior entry
There's a lot more in the database than posts and comments. We have favorites, flags, tags, MeFi Mail, internal logging/caching, and user data. And there are some hefty indexes on all of this data. I'm not sure how I calculated those numbers, but it's also possible I was just looking at the size of the comments themselves. Each comment also has a certain amount of overhead beyond the text itself. In 2009 we were also still gathering data from Twitter, Flickr, and Last.fm and that was a lot of data.
posted by pb (staff) at 4:42 PM on January 30, 2012
There's a lot more in the database than posts and comments. We have favorites, flags, tags, MeFi Mail, internal logging/caching, and user data. And there are some hefty indexes on all of this data. I'm not sure how I calculated those numbers, but it's also possible I was just looking at the size of the comments themselves. Each comment also has a certain amount of overhead beyond the text itself. In 2009 we were also still gathering data from Twitter, Flickr, and Last.fm and that was a lot of data.
posted by pb (staff) at 4:42 PM on January 30, 2012
Ah, got it. I was just surprised to see that comments/posts were apparently less than 50% of the database total (which was, in turn, less than 50% of the database + music total).
I also forgot to mention: mathowie was pretty consistently using a lowercase 'b' in 'Gb' and 'Mb' but I think it's clear from context that he always meant bytes and not bits. (The RAM example is a clear one.)
posted by nobody at 5:07 PM on January 30, 2012
I also forgot to mention: mathowie was pretty consistently using a lowercase 'b' in 'Gb' and 'Mb' but I think it's clear from context that he always meant bytes and not bits. (The RAM example is a clear one.)
posted by nobody at 5:07 PM on January 30, 2012
Yeah, it is surprising. And this got me thinking about how exactly that breaks down. And here's a handy chart.
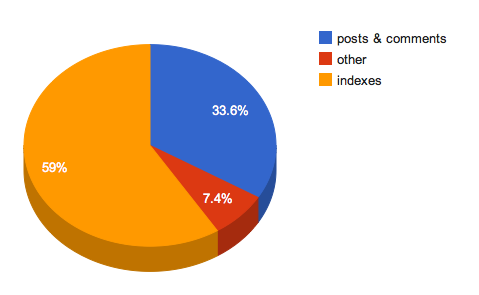
So, for the future record, I used this query to measure the database. I put the tables in two categories: posts/comments and other. And then I added up the size of all the indexes combined. I knew indexes were a big part of the database but I didn't realize it made up almost 60% of that 28 GB. Posts and comments make up 33.6% of the database, and 7.4% for other. I would have guessed that other would be higher than that.
posted by pb (staff) at 10:29 PM on January 30, 2012
{kind=link}
So, for the future record, I used this query to measure the database. I put the tables in two categories: posts/comments and other. And then I added up the size of all the indexes combined. I knew indexes were a big part of the database but I didn't realize it made up almost 60% of that 28 GB. Posts and comments make up 33.6% of the database, and 7.4% for other. I would have guessed that other would be higher than that.
posted by pb (staff) at 10:29 PM on January 30, 2012
For us non-silicon-based lifeforms, when you robots are talking about "indexes", what exactly does that mean? How does it relate to the human concept of an index?
I'm sorry, for someone who knows a lot about technology, I don't know shit about technology, and this is one of those things I've been wondering for a while.
posted by Rock Steady at 7:02 AM on January 31, 2012
I'm sorry, for someone who knows a lot about technology, I don't know shit about technology, and this is one of those things I've been wondering for a while.
posted by Rock Steady at 7:02 AM on January 31, 2012
For us non-silicon-based lifeforms, when you robots are talking about "indexes", what exactly does that mean?
Let's use comments here as an example. Comments are stored in a table in the database, which keeps track of the comment text, who posted it, when it was posted, which thread it was posted in, and a unique comment ID number. You can see the comment ID if you hover your mouse over a timetamp on a comment.
The comments table is (probably) stored in order of the comment ID number. So if you know this ID number, the server can find a comment in the comments table really fast. Sort of like how you can find a specific page number in book quite quickly, without having to go through it page-by-page from the beginning, because you know the page numbers are in order.
Which is great, but what if you need to retrieve a list of all the comments in one particular thread (to generate the page to display the thread)? Or pull up all the comments by one particular user (like some of the user activity pages do)?
Well, one way is to have the server just scan through the entire comments table from start to finish looking for comments with the right thread ID or user ID. But that's slow and inefficient, especially when there are millions of comments to look through, most of which aren't ones you want.
So to speed this up, we keep another little table called an index. This would have just two columns in it, say, thread ID number, and comment ID number. And it's sorted by thread ID. So if we want, for example, to pull up a list of all the comments in thread #21414 (which is this thread!), the server looks at that index, quickly finds its way to the entries for thread #21414 (which are all together) and then grabs the list of comment ID numbers for that thread.
And now that it has the comment ID numbers that it needs, it can go get the actual comments for this thread very quickly, instead of scanning through millions and millions of comments trying to find the right ones.
We might have another index that contains user ID and comment ID. So we can use it to quickly grab a list of all comment IDs for comments from one particular user, then go retrieve just those comments from the comments table.
It's fairly typical to have an index for just about any kind of ID field in the database in case you want to be able to search by that ID. And then there's also a full-text index, which is kind of the same idea but allows you to pull up a list of e.g. commment IDs containing a specific word (much like the index in a book gives you a list of pages that mention a word).
Does that help?
posted by FishBike at 7:25 AM on January 31, 2012
Let's use comments here as an example. Comments are stored in a table in the database, which keeps track of the comment text, who posted it, when it was posted, which thread it was posted in, and a unique comment ID number. You can see the comment ID if you hover your mouse over a timetamp on a comment.
The comments table is (probably) stored in order of the comment ID number. So if you know this ID number, the server can find a comment in the comments table really fast. Sort of like how you can find a specific page number in book quite quickly, without having to go through it page-by-page from the beginning, because you know the page numbers are in order.
Which is great, but what if you need to retrieve a list of all the comments in one particular thread (to generate the page to display the thread)? Or pull up all the comments by one particular user (like some of the user activity pages do)?
Well, one way is to have the server just scan through the entire comments table from start to finish looking for comments with the right thread ID or user ID. But that's slow and inefficient, especially when there are millions of comments to look through, most of which aren't ones you want.
So to speed this up, we keep another little table called an index. This would have just two columns in it, say, thread ID number, and comment ID number. And it's sorted by thread ID. So if we want, for example, to pull up a list of all the comments in thread #21414 (which is this thread!), the server looks at that index, quickly finds its way to the entries for thread #21414 (which are all together) and then grabs the list of comment ID numbers for that thread.
And now that it has the comment ID numbers that it needs, it can go get the actual comments for this thread very quickly, instead of scanning through millions and millions of comments trying to find the right ones.
We might have another index that contains user ID and comment ID. So we can use it to quickly grab a list of all comment IDs for comments from one particular user, then go retrieve just those comments from the comments table.
It's fairly typical to have an index for just about any kind of ID field in the database in case you want to be able to search by that ID. And then there's also a full-text index, which is kind of the same idea but allows you to pull up a list of e.g. commment IDs containing a specific word (much like the index in a book gives you a list of pages that mention a word).
Does that help?
posted by FishBike at 7:25 AM on January 31, 2012
Yeah, what FishBike said. One of the key things that make databases useful for dealing with large piles of data, that makes it more than just a big flat listing of data in funny clothing, is the way they trade disk space for computational efficiency. Any computational task you could hope to perform depends on both of those to some extent: you need to have information in memory (RAM in the short term, hard disk space in the long term), and you need to spend CPU cycles to perform calculations on that information.
So the tradeoff a database makes with indexing is that it pre-computes some tasks and writes the results down on disk so that it doesn't have to compute it every time. It costs you hard drive space but it makes any repetition of that task go much faster in the future.
This was a harder choice back when disk space was more expensive—you might have to think hard about which indexes are really important, you might limit your site's functionality a bit based on which kinds of search/lookup/query could actually be accomplished efficiently with the indexes you could afford to create—but it's less of an issue these days when a GB is something that costs a few cents instead of a few dollars or a few hundreds of dollars.
posted by cortex (staff) at 7:41 AM on January 31, 2012 [1 favorite]
So the tradeoff a database makes with indexing is that it pre-computes some tasks and writes the results down on disk so that it doesn't have to compute it every time. It costs you hard drive space but it makes any repetition of that task go much faster in the future.
This was a harder choice back when disk space was more expensive—you might have to think hard about which indexes are really important, you might limit your site's functionality a bit based on which kinds of search/lookup/query could actually be accomplished efficiently with the indexes you could afford to create—but it's less of an issue these days when a GB is something that costs a few cents instead of a few dollars or a few hundreds of dollars.
posted by cortex (staff) at 7:41 AM on January 31, 2012 [1 favorite]
I'll just add that in addition to the extra hard drive space, that pre-computing required to write the indexes has a CPU cost as well. So every time a comment is posted it's saved to the table and the myriad indexes involved with that comment. We're at a point now where we have enough extra CPU that it's not a big deal, but adding indexes with wild abandon could slow down adding and updating data.
So a standard problem is that a particular query is too slow. There are lots of ways to tackle that problem, and one powerful tool is indexing. As cortex mentioned, you can set up an index for that particular query. No other query in the system is going to use that index so you have to see if the potential gains are worth that speed trade-off on write. We have tools like the Database Engine Tuning Advisor that can recommend indexes and estimate performance gains. A 5% gain might not be worth the overhead, so you have to go for another tool in the toolbox like rewriting the query in a more efficient way or coming up with some other way to cache data ahead of time.
We slice up the same data into so many different views here that indexes are a big part of how we try to keep the site speedy.
posted by pb (staff) at 8:35 AM on January 31, 2012 [1 favorite]
So a standard problem is that a particular query is too slow. There are lots of ways to tackle that problem, and one powerful tool is indexing. As cortex mentioned, you can set up an index for that particular query. No other query in the system is going to use that index so you have to see if the potential gains are worth that speed trade-off on write. We have tools like the Database Engine Tuning Advisor that can recommend indexes and estimate performance gains. A 5% gain might not be worth the overhead, so you have to go for another tool in the toolbox like rewriting the query in a more efficient way or coming up with some other way to cache data ahead of time.
We slice up the same data into so many different views here that indexes are a big part of how we try to keep the site speedy.
posted by pb (staff) at 8:35 AM on January 31, 2012 [1 favorite]
Does that help?
Perfectly. You know, I actually understand "databases" (I've even created a rather nifty Access database that the pharmacy I work in is going to use to keep track of our compounded products), and I know that people talk about the MeFi (or other websites) "database", but I've never explicitly linked in my mind the two concepts -- that a website is basically just a publically accessible well-designed query of a big old database (I'm sure that is vastly simplifying the matter, but you know what I mean). Thanks!
posted by Rock Steady at 8:35 AM on January 31, 2012 [1 favorite]
Perfectly. You know, I actually understand "databases" (I've even created a rather nifty Access database that the pharmacy I work in is going to use to keep track of our compounded products), and I know that people talk about the MeFi (or other websites) "database", but I've never explicitly linked in my mind the two concepts -- that a website is basically just a publically accessible well-designed query of a big old database (I'm sure that is vastly simplifying the matter, but you know what I mean). Thanks!
posted by Rock Steady at 8:35 AM on January 31, 2012 [1 favorite]
I'm sure that is vastly simplifying the matter, but you know what I mean
No, it's a good way of thinking of it. Because that's what almost everything folks do on Mefi is: a way to trigger specific kinds of database queries, to interact with our database via a set of pre-established requests. Viewing a thread is just asking the db for a set of comments in order with details like username and post date and number-of-favorites displayed as well. Flagging something is inserting a new row into the flags table. Adding a comment is inserting a new row into the comments table (and, as pb notes, a number of other associated tables). Users don't need to think about it this way and most don't, but it absolutely is what's happening at a mechanical level.
That's part of why careful sanitization of user-provided data is such a basic important issue with any interactive site: when we strip forbidden content out of a submitted comment or post at submission time, it's not just a bid to control the visual presentation of content (no big tags, no image tags) or even to prevent nasty javascript exploits from being rendered on a page (XSS attacks); it's also an attempt to prevent malicious data from going into the database itself, to prevent the ill-intentioned from making the database do things its not supposed to do. The information-management strengths of a database are also a big vulnerability, and so one of the balances to be struck is between trusting the user and protecting the system.
posted by cortex (staff) at 9:05 AM on January 31, 2012
No, it's a good way of thinking of it. Because that's what almost everything folks do on Mefi is: a way to trigger specific kinds of database queries, to interact with our database via a set of pre-established requests. Viewing a thread is just asking the db for a set of comments in order with details like username and post date and number-of-favorites displayed as well. Flagging something is inserting a new row into the flags table. Adding a comment is inserting a new row into the comments table (and, as pb notes, a number of other associated tables). Users don't need to think about it this way and most don't, but it absolutely is what's happening at a mechanical level.
That's part of why careful sanitization of user-provided data is such a basic important issue with any interactive site: when we strip forbidden content out of a submitted comment or post at submission time, it's not just a bid to control the visual presentation of content (no big tags, no image tags) or even to prevent nasty javascript exploits from being rendered on a page (XSS attacks); it's also an attempt to prevent malicious data from going into the database itself, to prevent the ill-intentioned from making the database do things its not supposed to do. The information-management strengths of a database are also a big vulnerability, and so one of the balances to be struck is between trusting the user and protecting the system.
posted by cortex (staff) at 9:05 AM on January 31, 2012
The nifty Infodumpster has been updated to account for the new data entries. Looking at the list of longest FPPs, it looks like the modern megapost got started in late 2007/2008, went out of style for a bit in 2009, then exploded in popularity in 2010 and 2011. Earlier years are scattered near the top of the list, but they're all relatively short posts that either link every single word or cram several paragraphs of notes into multiple <abbr> tags.
posted by Rhaomi at 1:46 AM on February 1, 2012
posted by Rhaomi at 1:46 AM on February 1, 2012
The Infodump ... should now be back to updating regularly each weekend.
*polite nudge*
posted by Pronoiac at 1:19 PM on February 5, 2012
*polite nudge*
posted by Pronoiac at 1:19 PM on February 5, 2012
Hey, I didn't say WHEN on the weekend.
Although early in the morning on Sunday does seem like a good time, so I'll poke pb about it.
posted by cortex (staff) at 1:55 PM on February 5, 2012
Although early in the morning on Sunday does seem like a good time, so I'll poke pb about it.
posted by cortex (staff) at 1:55 PM on February 5, 2012
We have tools like the Database Engine Tuning Advisor that can recommend indexes and estimate performance gains.
Have you found that thing to be actually useful? I tried it a few times probably a decade ago or so, and found it recommended very complex indexes that were highly specific to one particular query and that didn't help performance much. I could do way better looking at the query execution plan and deciding from that what indexes to create. Or even just deciding looking at the general form of the query. Wondering if it's a more useful tool these days.
posted by FishBike at 3:08 PM on February 8, 2012
Have you found that thing to be actually useful? I tried it a few times probably a decade ago or so, and found it recommended very complex indexes that were highly specific to one particular query and that didn't help performance much. I could do way better looking at the query execution plan and deciding from that what indexes to create. Or even just deciding looking at the general form of the query. Wondering if it's a more useful tool these days.
posted by FishBike at 3:08 PM on February 8, 2012
Have you found that thing to be actually useful?
It is useful for me, yeah. You have to be careful and do a reality check on everything it recommends. It's like any computer-aided design. It's going to recommend some wacky things you wouldn't think of. Sometimes that's good, sometimes bad, sometimes just a starting point. It doesn't handle very complex queries very well, so I like to break things down into components and tune. It's a great "have I covered the basics?" double check.
posted by pb (staff) at 3:27 PM on February 8, 2012
It is useful for me, yeah. You have to be careful and do a reality check on everything it recommends. It's like any computer-aided design. It's going to recommend some wacky things you wouldn't think of. Sometimes that's good, sometimes bad, sometimes just a starting point. It doesn't handle very complex queries very well, so I like to break things down into components and tune. It's a great "have I covered the basics?" double check.
posted by pb (staff) at 3:27 PM on February 8, 2012
You are not logged in, either login or create an account to post comments
posted by cortex (staff) at 8:53 AM on January 30, 2012